真实静态网页爬取
2016里约奥运田径项目
小猪租房(广州)
里约奥运田径项目
因为女(自)票(己)想(想)看(装)田(逼)径,于是迫不及待地爬了一下里约的田径项目…
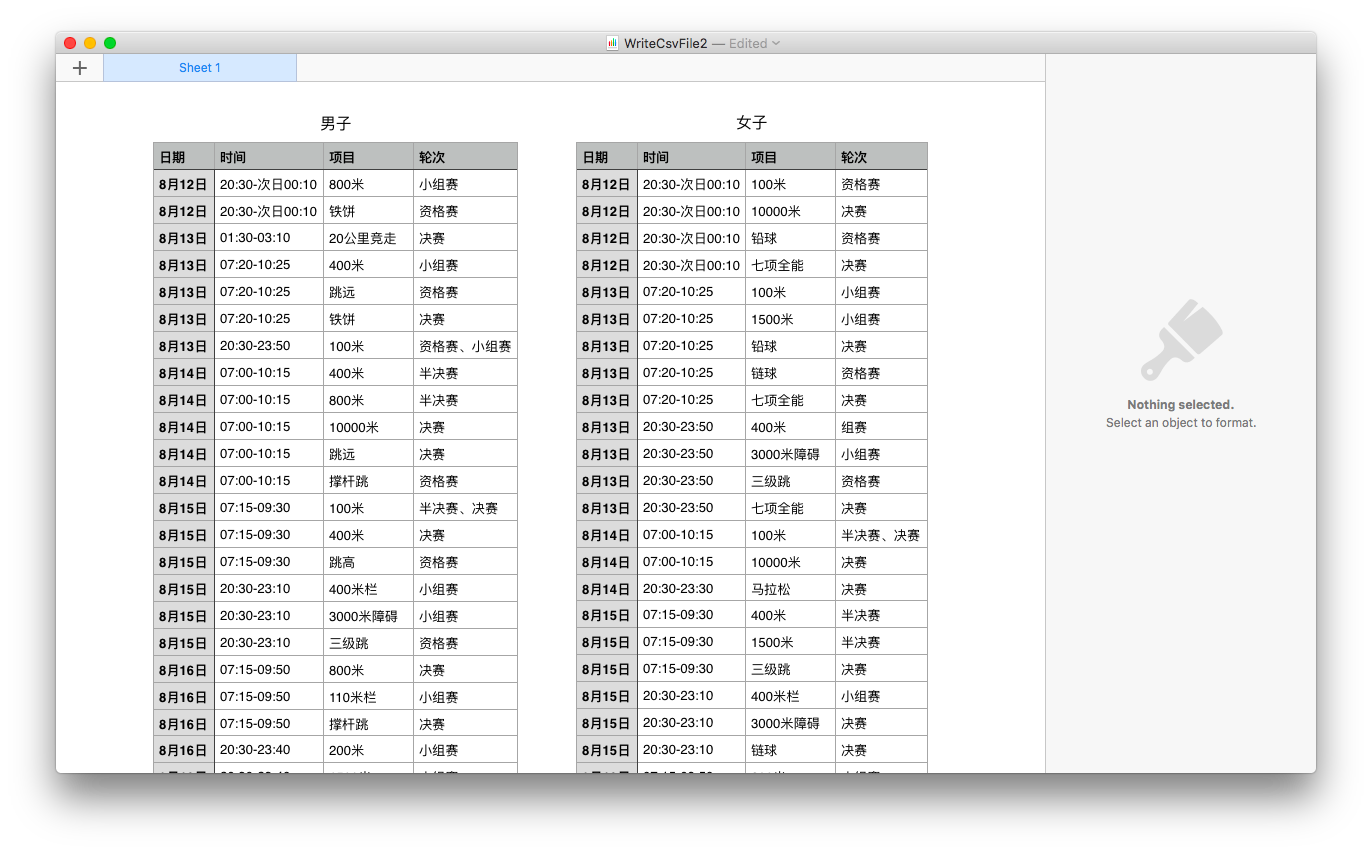
效果展示 数据链接_xlsx
数据链接_numbers
源站点 谷歌不知道为什么爬不了….
code 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 from bs4 import BeautifulSoupimport requestsimport timeimport csvmenu = ['http://gz.xiaozhu.com/search-duanzufang-p{}-0/' .format(str(i)) for i in range(1 ,16 )] url = 'http://www.ixueyi.com/yundong/293095.html' out = open("out.txt" ,"w" ) daySel = '#jc_nrong > div.TXCss107 > table > tbody > tr:nth-child(3) > td:nth-child(1)' timeSel = '#jc_nrong > div.TXCss107 > table > tbody > tr:nth-child(3) > td:nth-child(2)' headers = { 'User-Agent' : 'Mozilla/5.0 (Macintosh; Intel Mac OS X 10_11_5) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/51.0.2704.103 Safari/537.36' , 'Cookie' : 'NID=83=bg7QNR2QyqmCJMAb4JQZLk-HVFPL8aKM8EWsW9mbT8BfMslyf2uYA3gyIBdRUo_nSvekTZ9bu_6XHC2_8emosYlEIHbQe5XOFW_iIMK50IzdBIy6NSyr4thlswmjuqAIImVrA4e2t5uJtxD1H-Dy7dKoPxQLMBSYMWShPtqFBIMXj8_taezc1fcjXV4J5VVXnupDxk2Moq02PD-ekuAaoY9MPHtL; DV=kjjFsysMM5AYdPPDgiI1UyVX_W3FrAI' } outF = 'WriteCsvFile1.csv' csvf = open(outF, 'w' ) writer = csv.writer(csvf) writer.writerow(['日期' ,'时间' ,'项目' ,'轮次' ]) inType = ['Day' ,'Time' ,'Name' ,'Type' ] writer = csv.DictWriter(csvf,inType) def GetHost (url = url,headers = headers) : time.sleep(1 ) wb_data = requests.get(url) soup = BeautifulSoup(wb_data.text, 'lxml' ) titles = soup.select('#jc_nrong > div.TXCss107 > table > tbody > tr > td' ) Day = '8月12日' times = '01:30' types = '铁饼' sing = '小组' first = 1 for sth in titles: inf = sth.get_text() if (inf.find('月' ) != -1 ): Day = inf elif (inf.find(':' ) != -1 ): times = inf elif (inf.find('赛' ) != -1 ): if (first): first=0 pass else : sing = inf writer.writerow(dict(Day=Day,Time=times,Name=types,Type=sing)) elif (inf.find('<class \'type\'>' ) == -1 ): types = inf GetHost() 没close文件...是不是会挂w
笔记 writen 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 get /page_one.html HTTP/1.1 Host: www.sample.com Response status_code: 200 inspect -> Doc -> network -> cookie作为登录状态 显示网页源代码 如果能唯一定位那么就是正确的 找到更为简单方法描述 1. soup.select('div.property_title > a[target = "_ blank]") - 这样抓取到了不想要的东西.. 对比两个不一样的地方 + 特定属性 2. soup.select('img[width = "160']') 特定属性 - 抓取的所有都是同一个地址: 网站做了反爬取部分 - 爬取移动端页面... 3. 父级标签 多对一列表解析式 urls = ['....{}....'.format(str(i)) for i in range(30,930,30)]]
code 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 from bs4 import BeautifulSoupimport requestsimport timeurl = 'http://renld.cn/' wb_data = requests.get(url) soup = BeautifulSoup(wb_data.text,'lxml' ) headers = { 'Uesr-Agent' : '...' 'Cookie' : '...' } url_saves = './' time.sleep(2 ) wb_data = requests.get(url_saves, headers = headers) soup = BeautifulSoup(wb_data.text,'lxml' )
Task1 Task
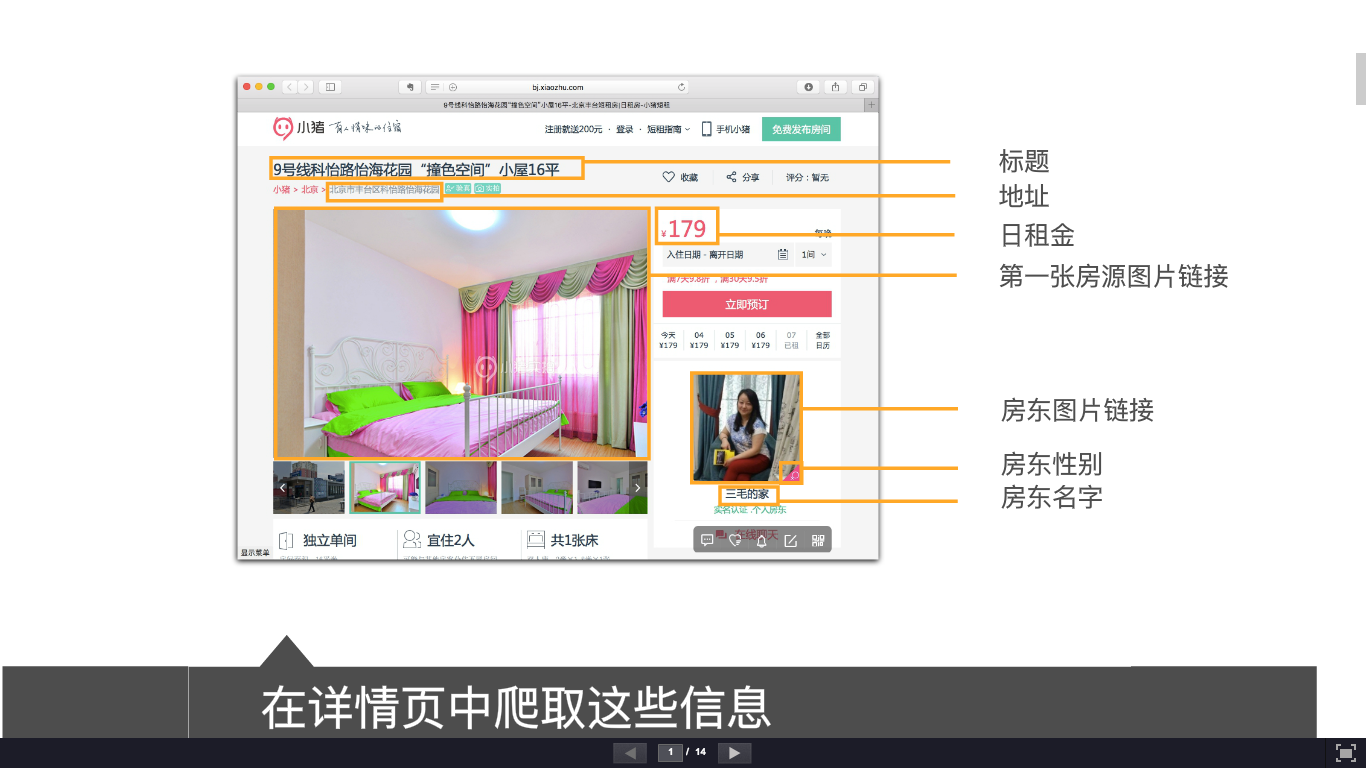
CODE 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 from bs4 import BeautifulSoupimport requestsimport timeurl = 'http://gz.xiaozhu.com/fangzi/1700198435.html' headers = { 'User-Agent' : 'Mozilla/5.0 (Macintosh; Intel Mac OS X 10_11_5) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/51.0.2704.103 Safari/537.36' , 'Cookie' : 'abtest_ABTest4SearchDate=b; xzuuid=334a0f71; _gat_UA-33763849-7=1; __utmt=1; OZ_1U_2282=vid=v7a566a4734c93.0&ctime=1470458319<ime=1470458217; OZ_1Y_2282=erefer=-&eurl=http%3A//bj.xiaozhu.com/&etime=1470457507&ctime=1470458319<ime=1470458217&compid=2282; _ga=GA1.2.206747787.1470457508; __utma=29082403.206747787.1470457508.1470457508.1470457508.1; __utmb=29082403.13.10.1470457508; __utmc=29082403; __utmz=29082403.1470457508.1.1.utmcsr=(direct)|utmccn=(direct)|utmcmd=(none)' } def GetHost (url = url,headers = headers) : wb_data = requests.get(url, headers=headers) soup = BeautifulSoup(wb_data.text, 'lxml' ) title = soup.select('body > div.wrap.clearfix.con_bg > div.con_l > div.pho_info > h4 > em' ) address = soup.select('body > div.wrap.clearfix.con_bg > div.con_l > div.pho_info > p > span' ) Add = address[0 ].get_text() Addr = Add[0 :Add.find('\n' )] DailyCost = soup.select('div.day_l > span' ) imgs = soup.select('#detailImageBox > div.pho_show_l > div > div > img' ) hosterImg = soup.select('#floatRightBox > div.js_box.clearfix > div.member_pic > a > img' ) sexN = soup.select('#floatRightBox > div.js_box.clearfix > div.w_240 > h6 > span' ) if sexN[0 ].get('member_boy_ico' ) != None : sex = 'girl' else : sex = 'boy' name = soup.select('#floatRightBox > div.js_box.clearfix > div.w_240 > h6 > a' ) inf = dict(title=title[0 ].get_text(),address=Addr,DailyCost=DailyCost[0 ].get_text(), Bigimg=imgs[0 ].get('src' ),hosterImg=hosterImg[0 ].get('src' ),sex=sex,name=name[0 ].get_text()) print(inf,sep='\n' ) return (inf) if __name__ == '__main__' : GetHost()
print 1 {'sex' : 'boy' , 'Bigimg' : 'http://image.xiaozhustatic1.com/00,800,533/4,0,58,6360,1800,1200,4a7bcf82.jpg' , 'hosterImg' : 'http://image.xiaozhustatic1.com/21/3,0,60,4932,252,252,82759f23.jpg' , 'title' : '珠江边主卧180°江景 近广州塔海心沙近地铁' , 'name' : '大卷' , 'DailyCost' : '289' , 'address' : '广东省广州市海珠区海琴湾' }
Question
(基本解决)为什么不能像教程那样通过width抓取图片
(???)为什么抓取的图片打不开
(???)由于得到的是list,不能直接用get,那么更好办法使用get…(我是用取第一位[0])
Task2 Task
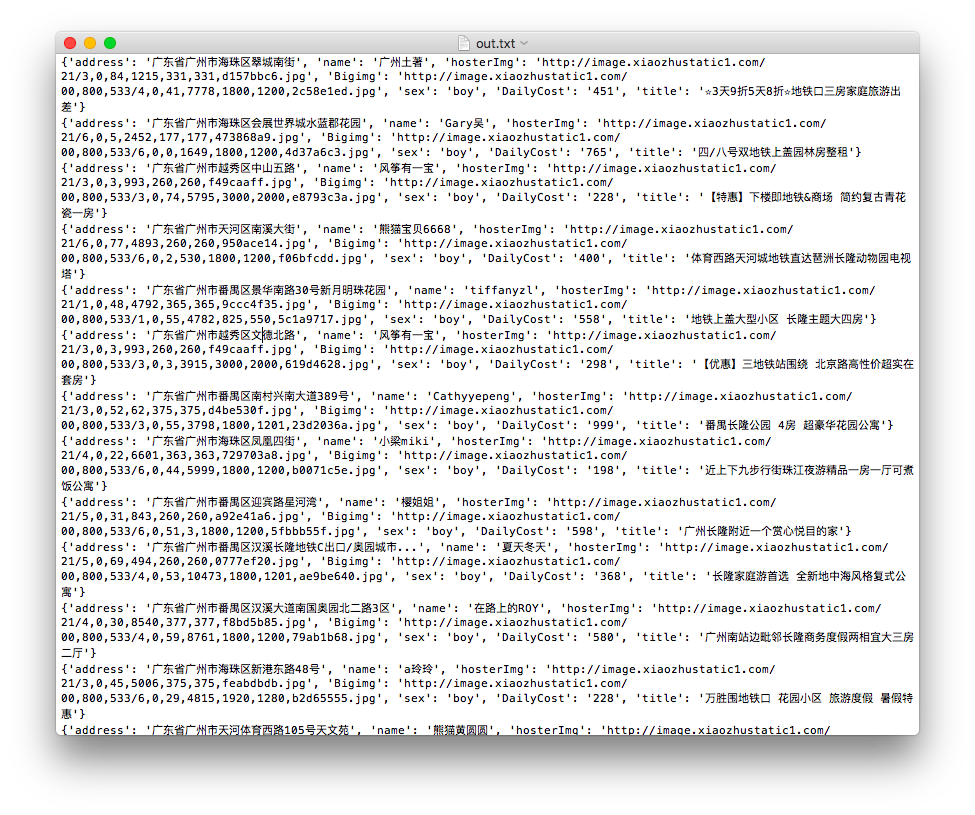
code 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 from bs4 import BeautifulSoupimport requestsimport timemenu = ['http://gz.xiaozhu.com/search-duanzufang-p{}-0/' .format(str(i)) for i in range(1 ,16 )] url = 'http://gz.xiaozhu.com/fangzi/1700198435.html' out = open("out.txt" ,"w" ) headers = { 'User-Agent' : 'Mozilla/5.0 (Macintosh; Intel Mac OS X 10_11_5) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/51.0.2704.103 Safari/537.36' , 'Cookie' : 'abtest_ABTest4SearchDate=b; xzuuid=334a0f71; _gat_UA-33763849-7=1; __utmt=1; OZ_1U_2282=vid=v7a566a4734c93.0&ctime=1470458319<ime=1470458217; OZ_1Y_2282=erefer=-&eurl=http%3A//bj.xiaozhu.com/&etime=1470457507&ctime=1470458319<ime=1470458217&compid=2282; _ga=GA1.2.206747787.1470457508; __utma=29082403.206747787.1470457508.1470457508.1470457508.1; __utmb=29082403.13.10.1470457508; __utmc=29082403; __utmz=29082403.1470457508.1.1.utmcsr=(direct)|utmccn=(direct)|utmcmd=(none)' } def GetHost (url = url,headers = headers) : time.sleep(1 ) wb_data = requests.get(url, headers=headers) soup = BeautifulSoup(wb_data.text, 'lxml' ) title = soup.select('body > div.wrap.clearfix.con_bg > div.con_l > div.pho_info > h4 > em' ) address = soup.select('body > div.wrap.clearfix.con_bg > div.con_l > div.pho_info > p > span' ) Add = address[0 ].get_text() Addr = Add[0 :Add.find('\n' )] DailyCost = soup.select('div.day_l > span' ) imgs = soup.select('#detailImageBox > div.pho_show_l > div > div > img' ) hosterImg = soup.select('#floatRightBox > div.js_box.clearfix > div.member_pic > a > img' ) sexN = soup.select('#floatRightBox > div.js_box.clearfix > div.w_240 > h6 > span' ) if sexN[0 ].get('member_boy_ico' ) != None : sex = 'girl' else : sex = 'boy' name = soup.select('#floatRightBox > div.js_box.clearfix > div.w_240 > h6 > a' ) inf = dict(title=title[0 ].get_text(),address=Addr,DailyCost=DailyCost[0 ].get_text(), Bigimg=imgs[0 ].get('src' ),hosterImg=hosterImg[0 ].get('src' ),sex=sex,name=name[0 ].get_text()) return (inf) ''' #page_list > ul > li:nth-child(1) > a ''' for first in menu: web_data = requests.get(first) Soup = BeautifulSoup(web_data.text, 'lxml' ) addr = Soup.select('#page_list > ul > li > a' ) for p in addr: if (p.get('href' ) != None ): print(GetHost(p.get('href' )), file=out)
print
Question
(已解决)爬取太慢了QAQ..怎么设延时比较好,怎么知道自己有没有被封ip……
(已解决)爬取的信息能不能丢到csv文件里去..txt实在太丑……
(已解决)cookies是不是应该加密(不直接放到博客上…)
总结 真实网页的爬取果然比静态难很多啊..开个vpn把电脑先丢到那里爬咯…300组数据orz
哈哈哈爬了几十分钟爬完了,链接在评论里面
CSV 晚上写了一个txtTocsv脚本转换成表格形式
1 2 3 4 5 6 7 8 9 10 11 import csvinfo = ['title' ,'name' ,'DailyCost' ,'hosterImg' ,'Bigimg' ,'address' ,'sex' ] with open('1_3out.txt' ,"r" ) as txtf, open('WriteCsvFile.csv' , 'w' ) as csvf: writer = csv.writer(csvf) writer.writerow(info) writer = csv.DictWriter(csvf,info) for i in txtf: k = eval(i) writer.writerow(k)
效果展示
老师答复
因为网站做了更新,所以做教程的时候可以抓取,但是现在已经不能用教程里的那种方法使用width去定位
图片的后缀有正确吗,如果正确的话还打不开,那换种方法看看,去我们的问题集里有关于如何下载图片的方法。
cookie加密了,网站还懂得认你的身份吗?所以不加
延迟的话一般设置2,3秒差不多,只有一直出现网络被断开就是被禁了,如果还是被禁的话,再调大一点,解决这个问题的根本方法还是使用代理
<
python实战计划 动态数据爬取
python实战计划 爬取商品信息
>