对58同城下手
Task1
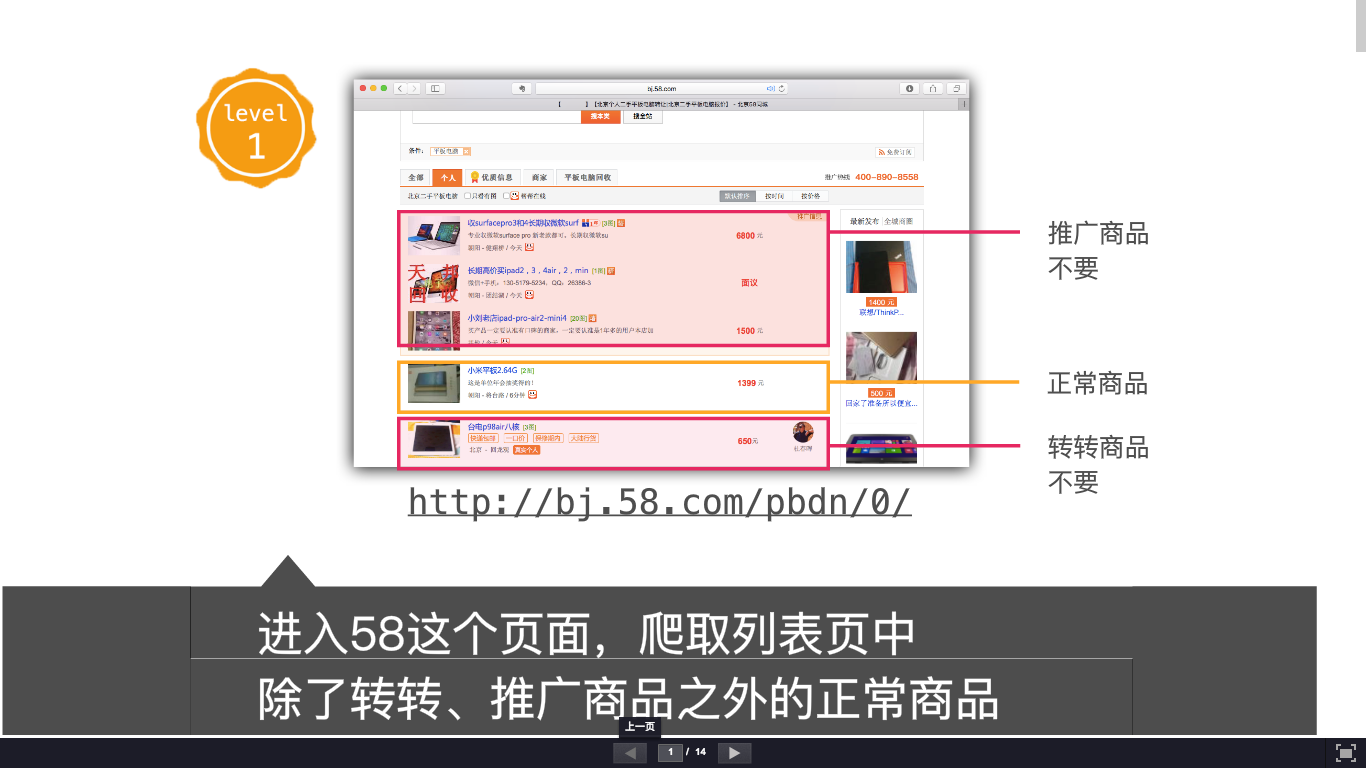
SubTask1 58二手市场类别页面
Aim
(因为改版..只能爬取转转商品)
Results
Code
- 本来想爬取每个位置,删除推广的,然后发现爬了之后就没有推广,于是直接爬了
- 接地气一点..换个URL爬
- 注意爬取图片时候用lazy_url
- 清理一下信息,用
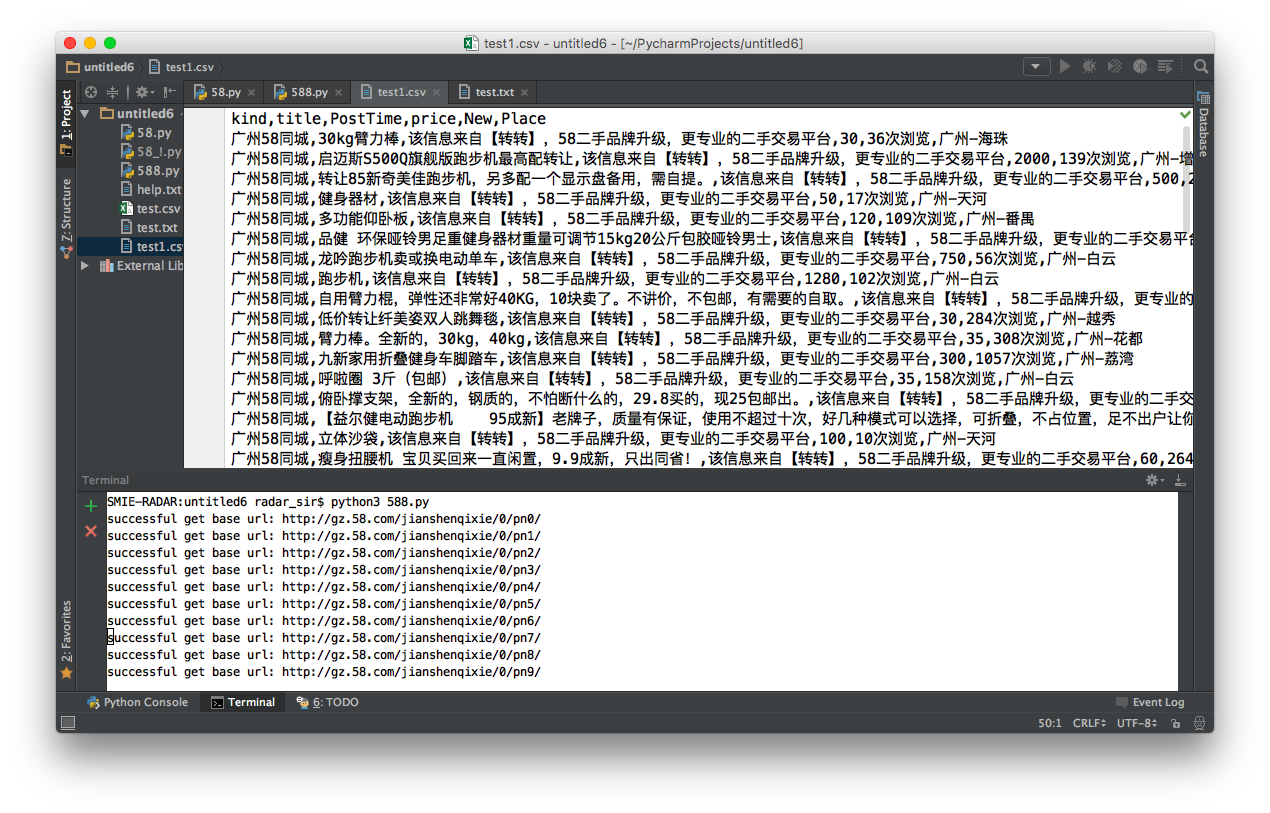
strip() - 爬了300条信息,增加了url
1 | #-*- coding: utf8 -*- |
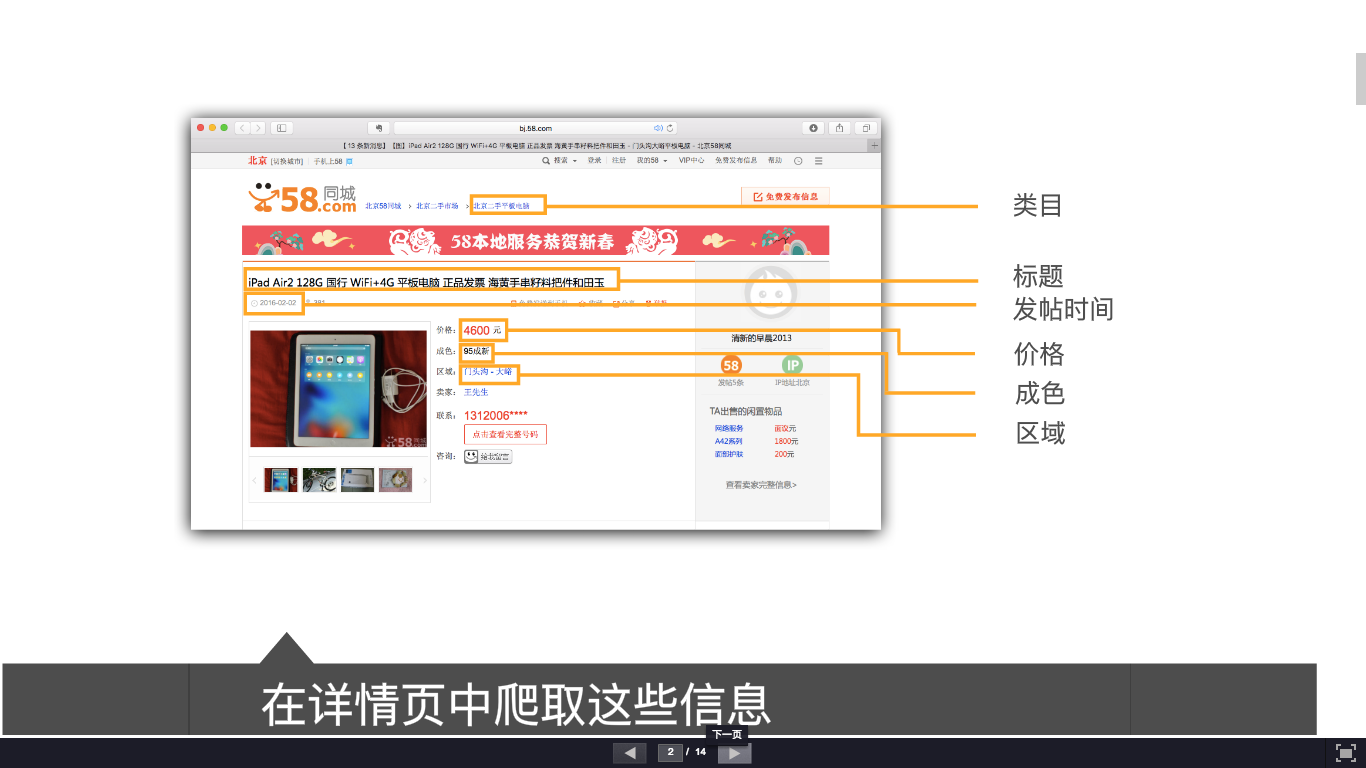
SubTask2 58二手市场类别页面
想必这个要跑很久…吃饭前写完丢在哪里跑吧
结果是….
吃了饭回来发现…..
有个函数参数写多了………….
Results
同样因为页面改版,同样是上一个里面得到的链接,用上一步得到的url进一步爬取呗:)
爬取浏览量似乎很简单,爬不到新旧程度,和发帖时间
1 | PostTimes = [PostTimes[1]] #补上这句后就能爬取到描述了..没想到那里有两个相同标签QAQ |
Code
1 | #-*- coding: utf8 -*- |
Review
第一个任务算是一个小复习吧:
requests处理网络请求
BeautifulSoup解析网页
soup.select(titleSel)得到元素
kind.get_text() && kind.get( ‘src’ )
csv.writer(testFile) && writer.writerow(info) && writer = csv.DictWriter(testFile, info)
自己生成重复太多的info代码
time.sleep
headers
-*- coding: utf8 —
Task2 爬取JS浏览量
58同城改版了…
似乎浏览量可以直接爬取……
(说实话 改版之后漂亮很多)
于是用自己博客做试验咯…..
打开了
当初换了域名后浏览量清零
暴怒关闭的浏览量统计…….(厚颜)
inspect > sources > busuanzi > …
然后发现不算子爬取不了???????
1 | #-*- coding: utf8 -*- |
视频笔记
- 由于58同城特殊性,可以从title爬取信息
soup.title.text url.split('.')[-1].strip('x.shtml')得到id- … if (…) else none
ReadMores
BeautifulSoup
output
prettify() 方法将Beautiful Soup的文档树格式化后以Unicode编码输出,每个XML/HTML标签都独占一行
get_text()方法,这个方法获取到tag中包含的所有文版内容包括子孙tag中的内容,并将结果作为Unicode字符串返回:1
soup.get_text("|", strip=True) 第一个参数是分割,第二个是去除空白
偏门方法
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22soup.title
# <title>The Dormouse's story</title>
通过点取属性的方式只能获得当前名字的第一个tag:
soup.p
# <p class="title"><b>The Dormouse's story</b></p>
soup.p['class']
soup.title.name
# u'title'
soup.a
# <a class="sister" href="http://example.com/elsie" id="link1">Elsie</a>
append()
Tag.append() 方法想tag中添加内容,就好像Python的列表的 .append() 方法:
soup = BeautifulSoup("<a>Foo</a>")
soup.a.append("Bar")
soup
# <html><head></head><body><a>FooBar</a></body></html>
soup.a.contents
# [u'Foo', u'Bar']
主要方法
1 |
|
正则表达式
如果传入正则表达式作为参数,Beautiful Soup会通过正则表达式的 match() 来匹配内容.下面例子中找出所有以b开头的标签,这表示\
1 | import re |
函数
1 | def has_class_but_no_id(tag): |