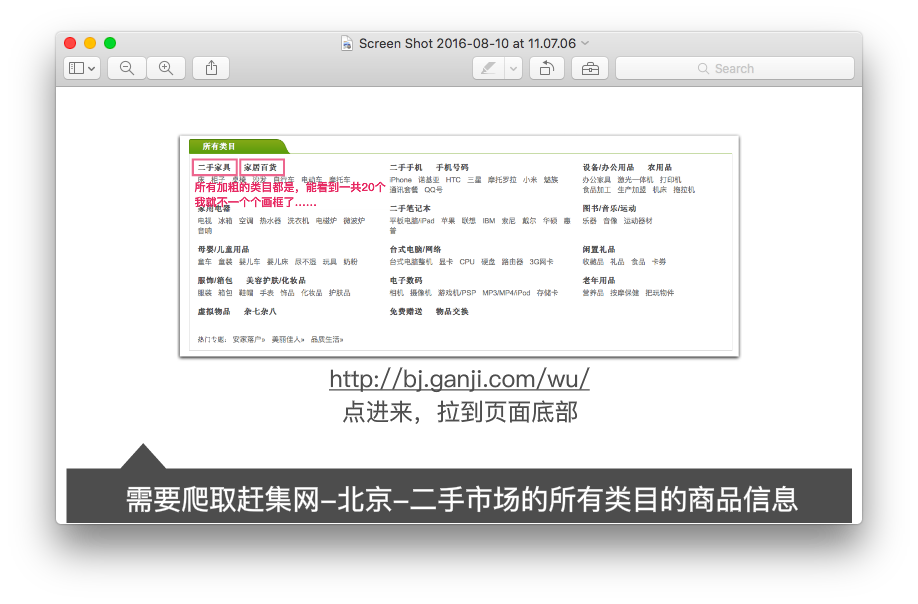
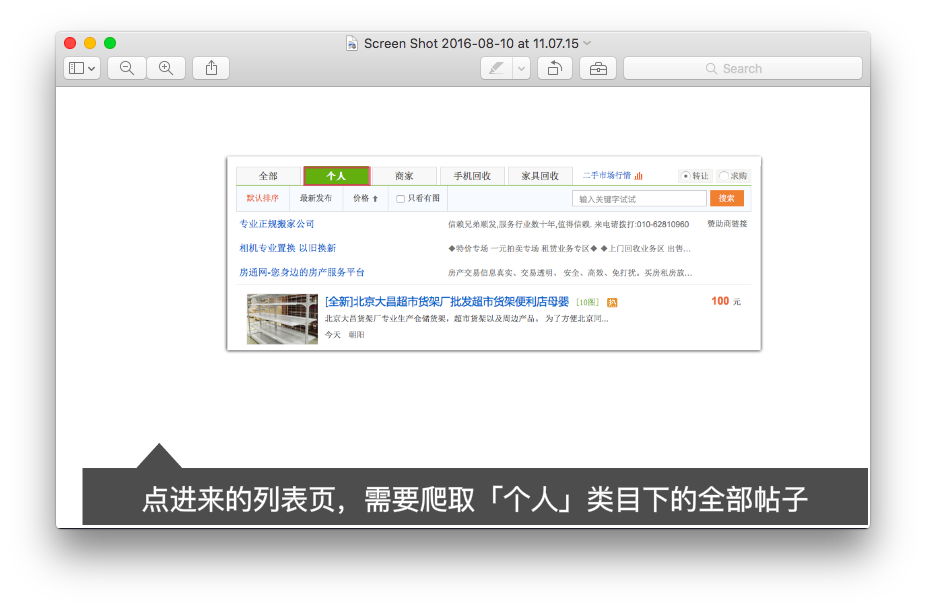
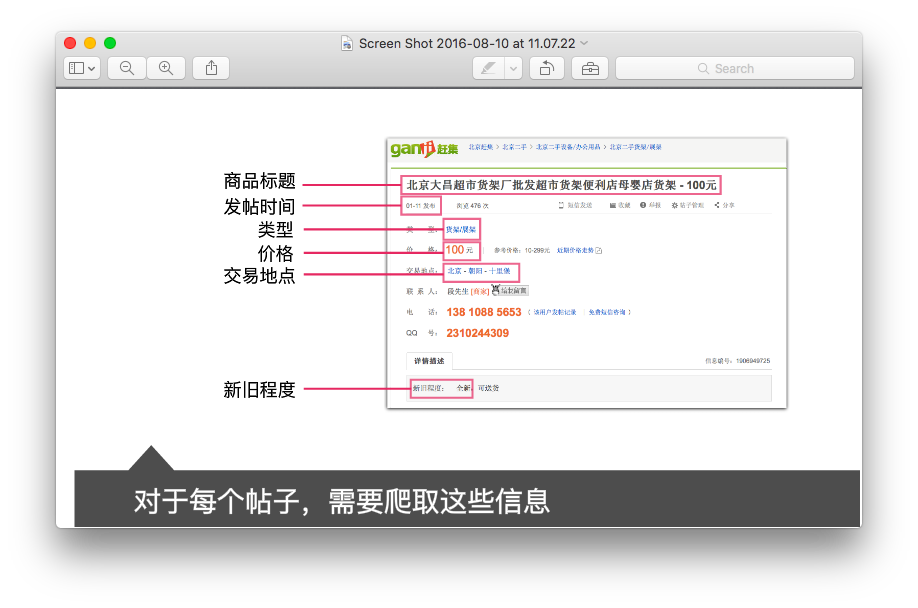
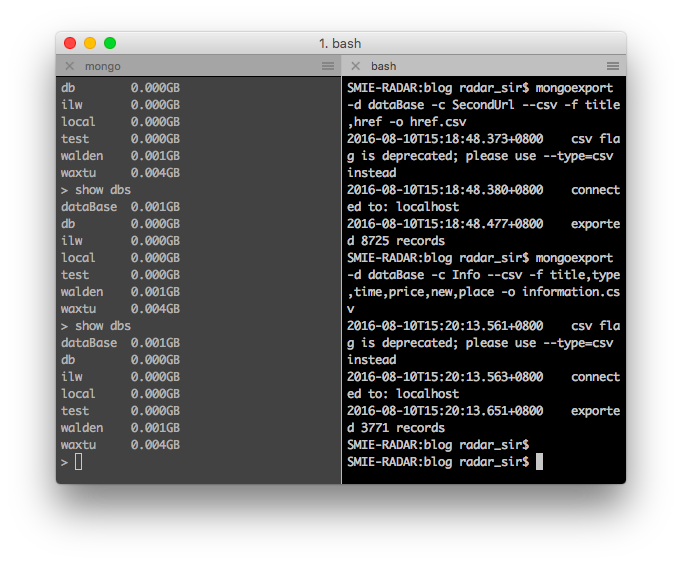
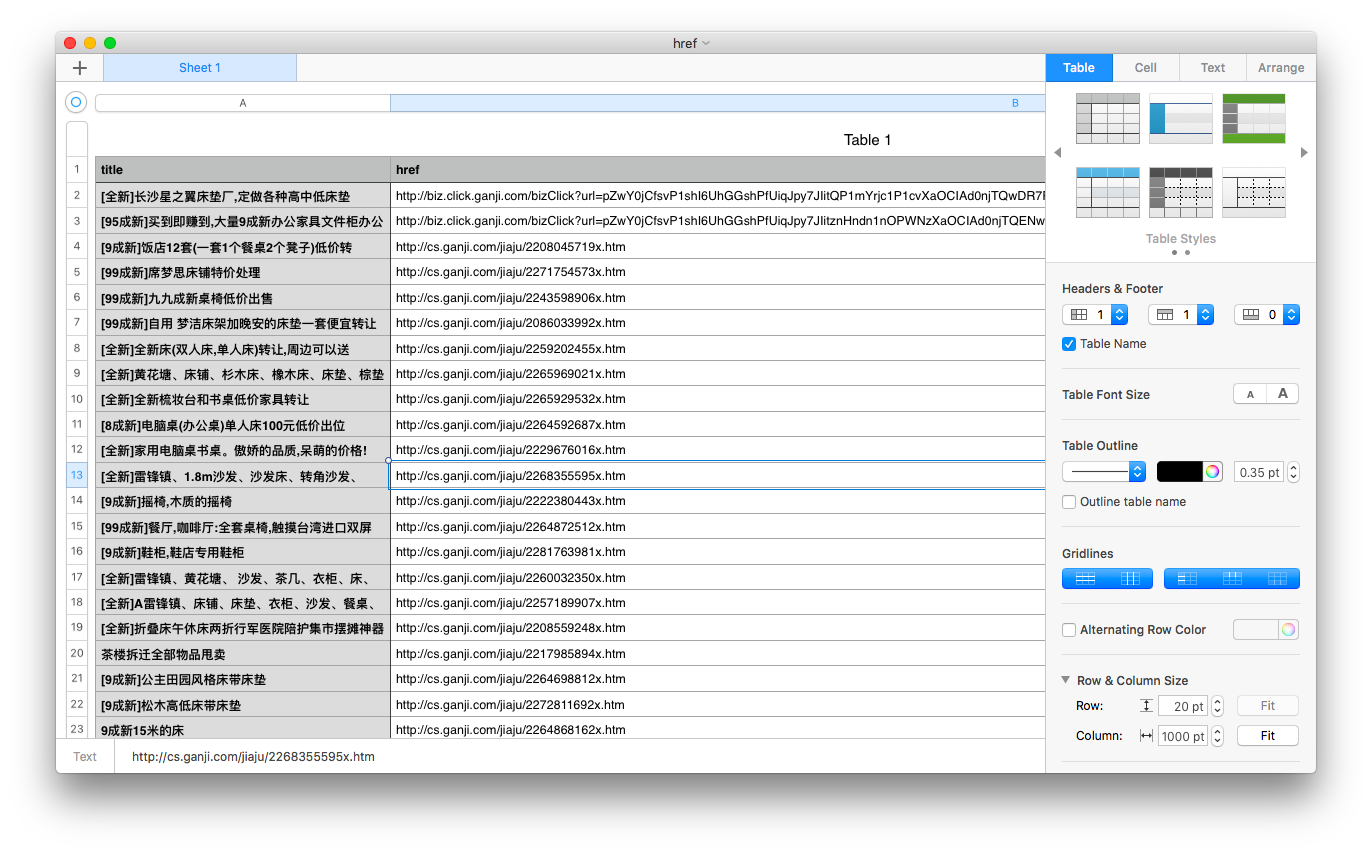
Fail to Get Info fromhttp://cs.ganji.com/shouji/2245928138x.htm Fail to Get Info fromhttp://cs.ganji.com/shouji/2245928138x.htm Fail to Get Info fromhttp://cs.ganji.com/shouji/2201642961x.htm Fail to Get Info fromhttp://cs.ganji.com/shouji/2201642961x.htm Fail to Get Info fromhttp://cs.ganji.com/shouji/2178792516x.htm Fail to Get Info fromhttp://cs.ganji.com/shouji/2178792516x.htm
另外没有报错????打开上述页面发现是被买走了
Code
封装Soup
1 2 3 4 5 6 7 8 9 10 11 12
defGetSoup(url,buquan=1): if buquan: wb_data = requests.get((BaseUrl + url),timeout=2) # 因为有的页面需要前缀. else: wb_data = requests.get(url) wb_data.encoding = 'utf8'# 加上这句否则会乱码!!! if wb_data.status_code == 200: soup = BeautifulSoup(wb_data.text,'lxml') return soup else: print('Fail to Get Info from'+url) returnNone
得到channel
1 2 3 4 5 6 7 8 9 10 11 12
TypeSel = '#wrapper > div.content > div > div > dl > dt > a'
defGetChannal(url): soup = GetSoup(url) if soup == None: returnNone else: types = soup.select(TypeSel) for type in types: href = type.get('href') title = type.get_text() FirstUrl.insert_one(dict(title=title,href=href))
GoodSel = '#wrapper > div.leftBox > div.layoutlist > dl > dd.feature > div > ul > li > a'
ThirdSet = set()
defGetGoods(url): soup = GetSoup(url) if soup != None: goods = soup.select(GoodSel) for good,p in zip(goods,range(1,10)): title = good.get_text().strip() href = good.get('href') data = dict(title=title,href=href) if data['href'] in ThirdSet: returnFalse else: ThirdSet.add(data['href']) SecondUrl.insert_one(data) returnTrue else: returnFalse defGetGoodsUrl(): for up in FirstUrl.find(): base = up['href'] for p in range(1, 10000): st = base + 'o' + str(p) + '/' try: if GetGoods(st) == False: print(base, 'end at', str(p))#爬取成功 break except: print('error in page', st)#有bug pass
headers = { 'Cookie':'ganji_uuid=3031153094415879005517; ganji_xuuid=3d4ba517-3b7d-4f20-e0d7-05de7a77b9c9.1459734446990; t3=2; statistics_clientid=me; __utmt=1; GANJISESSID=50071f0ac4021a7aa6fcfc7c52f229fa; STA_DS=1; lg=1; ganji_login_act=1470799155185; citydomain=cs; _gl_tracker=%7B%22ca_source%22%3A%22www.baidu.com%22%2C%22ca_name%22%3A%22-%22%2C%22ca_kw%22%3A%22-%22%2C%22ca_id%22%3A%22-%22%2C%22ca_s%22%3A%22seo_baidu%22%2C%22ca_n%22%3A%22-%22%2C%22ca_i%22%3A%22-%22%2C%22sid%22%3A40680747040%7D; __utma=32156897.1667757214.1468391541.1468391541.1470799081.2; __utmb=32156897.7.10.1470799081; __utmc=32156897; __utmz=32156897.1470799081.2.2.utmcsr=baidu|utmccn=(organic)|utmcmd=organic', 'User-Agent':'Mozilla/5.0 (Macintosh; Intel Mac OS X 10_11_5) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/52.0.2743.116 Safari/537.36' }
defGetSoup(url,buquan=1): if buquan: wb_data = requests.get((BaseUrl + url),timeout=2) else: wb_data = requests.get(url) wb_data.encoding = 'utf8'# 加上这句否则会乱码!!! if wb_data.status_code == 200: soup = BeautifulSoup(wb_data.text,'lxml') return soup else: print('Fail to Get Info from'+url) returnNone
TypeSel = '#wrapper > div.content > div > div > dl > dt > a'
defGetChannal(url): soup = GetSoup(url) if soup == None: returnNone else: types = soup.select(TypeSel) for type in types: href = type.get('href') title = type.get_text() FirstUrl.insert_one(dict(title=title,href=href))
GoodSel = '#wrapper > div.leftBox > div.layoutlist > dl > dd.feature > div > ul > li > a'
ThirdSet = set()
defGetGoods(url): soup = GetSoup(url) if soup != None: goods = soup.select(GoodSel) for good,p in zip(goods,range(1,10)): title = good.get_text().strip() href = good.get('href') data = dict(title=title,href=href) if data['href'] in ThirdSet: returnFalse else: ThirdSet.add(data['href']) SecondUrl.insert_one(data) returnTrue else: returnFalse
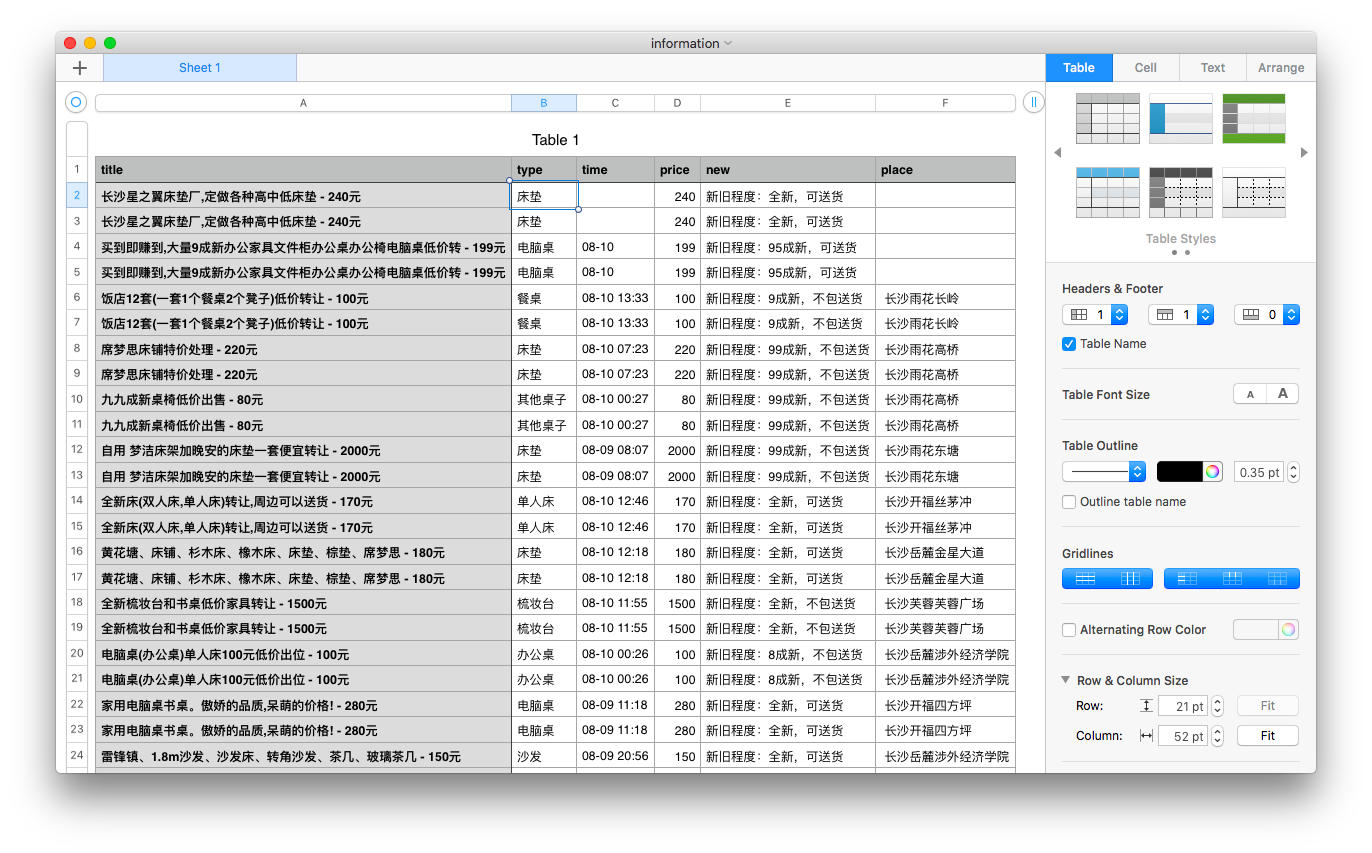
ttSel = '#wrapper > div.content.clearfix > div.leftBox > div.col-cont.title-box > h1' tmSel = '#wrapper > div.content.clearfix > div.leftBox > div.col-cont.title-box > div > ul.title-info-l.clearfix > li > i' tpSel = '#wrapper > div.content.clearfix > div.leftBox > div > div > ul > li > span > a' pcSel = '#wrapper > div.content.clearfix > div.leftBox > div > div > ul > li > i.f22.fc-orange.f-type' plSel = '#wrapper > div.content.clearfix > div.leftBox > div > div > ul > li > a' newSel = '#wrapper > div.content.clearfix > div.leftBox > div > div.det-summary > div > div.second-dt-bewrite > ul > li'
defGetGoodfInfo(url): soup = GetSoup(url,buquan=0) if soup != None: titles = soup.select(ttSel)[0].get_text() timers = soup.select(tmSel)[0].get_text().split('\\')[0].strip().split('\xa0')[0] if soup.select(tmSel) != [] elseNone types = soup.select(tpSel)[5].get_text() prices = soup.select(pcSel)[0].get_text() places = soup.select(plSel) if len(places) > 4: place = ''.join(places[i].get_text() for i in range(1,4)) else: place = None news = soup.select(newSel)[0].get_text().replace('\n','').replace(' ','').strip() if soup.select(newSel) != [] elseNone #print('place',place) #print('type',types) data = dict(title=titles,time=timers,type=types,price=prices,place=place,new=news) #print(data) Info.insert_one(data)
defGetGoodsUrl(): for up in FirstUrl.find(): base = up['href'] for p in range(1, 10000): st = base + 'o' + str(p) + '/' try: if GetGoods(st) == False: print(base, 'end at', str(p)) break except: print('error in page', st) pass
if __name__ == '__main__': GetChannal(ErShouUrl) GetGoodsUrl() for url in SecondUrl.find(): GetGoodfInfo(url['href']) try: GetGoodfInfo(url['href']) except Exception as e: print(str(e), 'fail to get ', url['href']) pass
心得与疑问
笔记
把’>’改成’ ‘之后不一定是严格下一级元素
访问量高的网站对于同一个ip的频次会有限制
lambda x:x.text
import lxml解析会快很多
try少量还行,,大量bug太多还是得debug
1 2 3 4 5
try: GetGoodfInfo(url['href']) except Exception as e: print(str(e), 'fail to get ', url['href']) pass