300条广州号码
笔记
- 观察页面特征
- 不同区域数目问题
- 设计工作流程(设计两个爬虫)
- 增加页面判断,错误页面不予爬取
Aim
效果
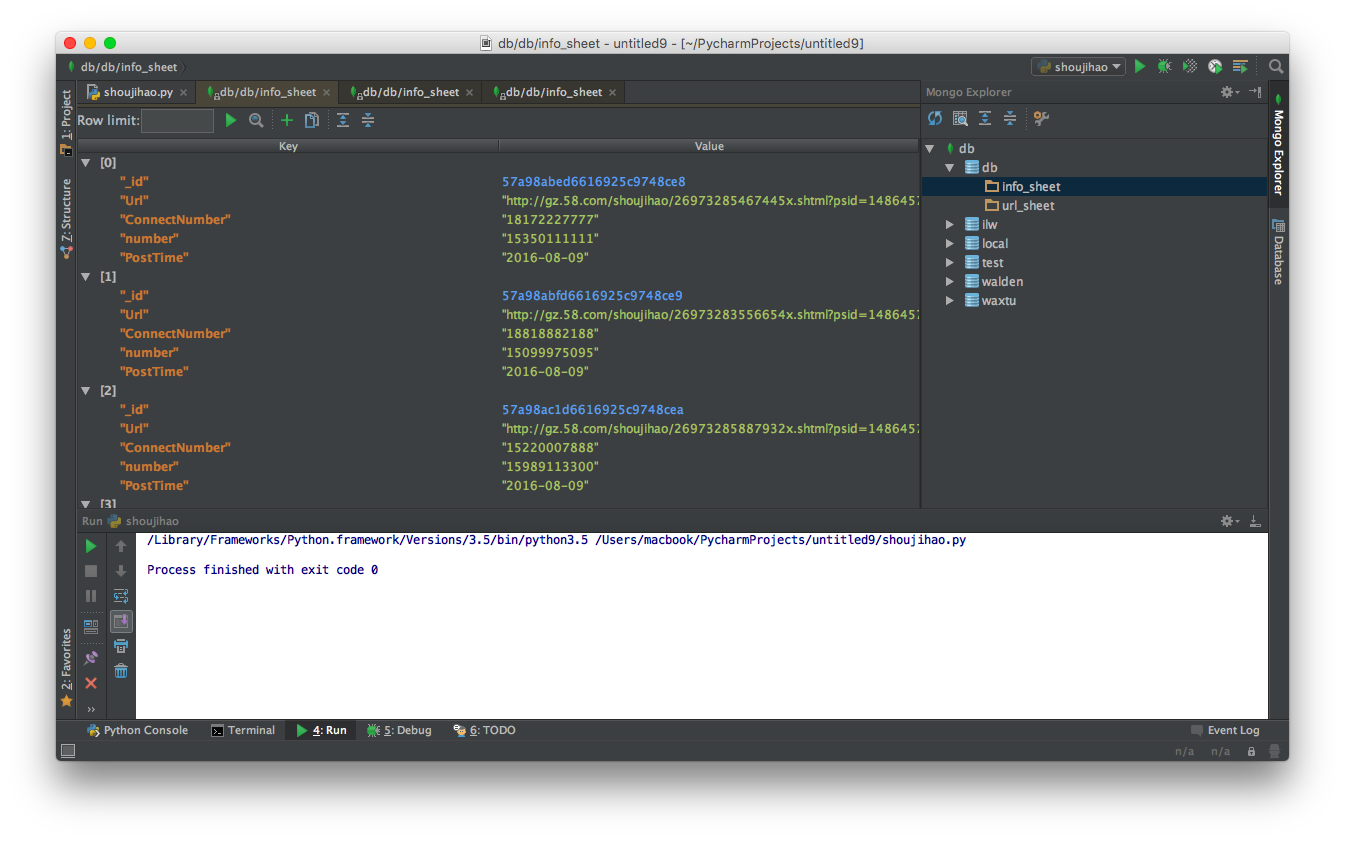
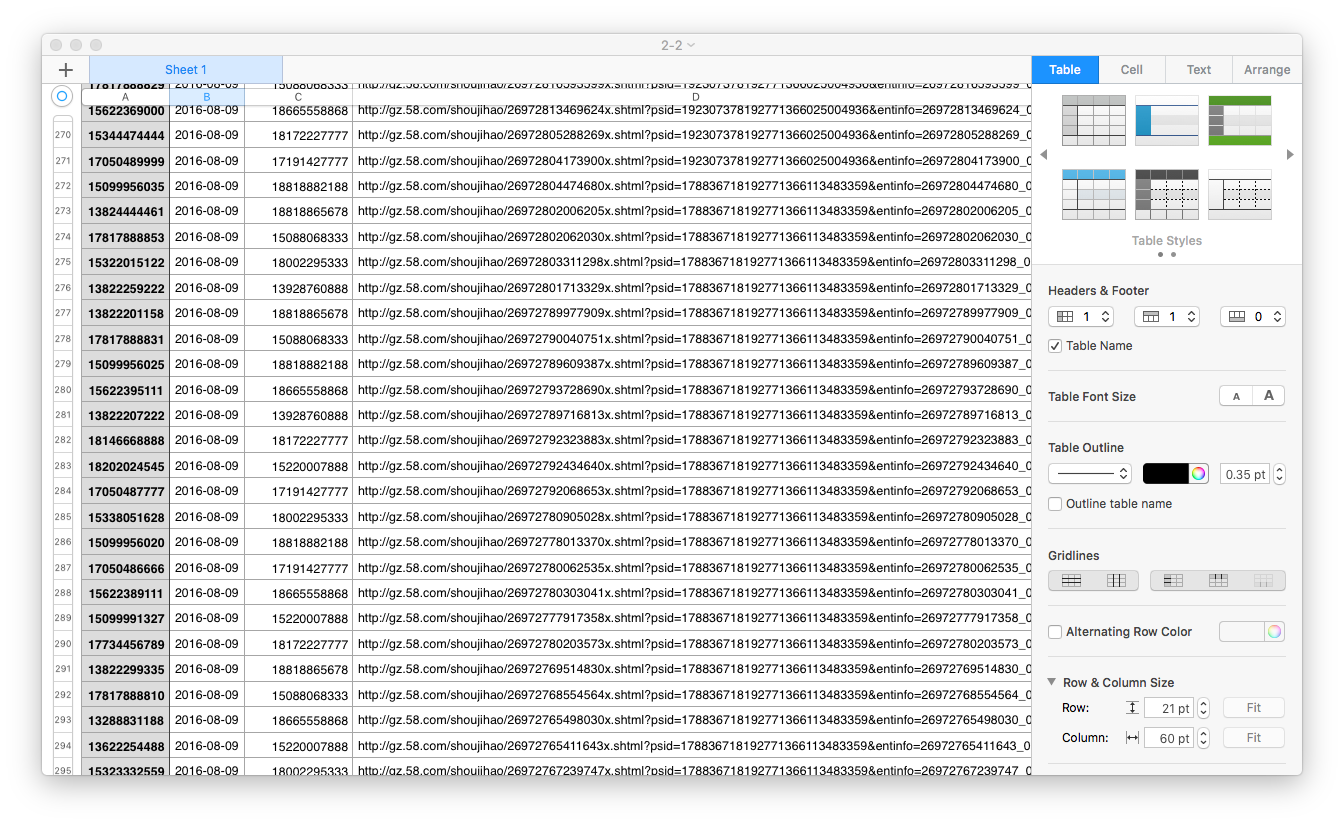
输出
Code
挑选页面花了好久时间…
还有对于404页面排除
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
71
72
73
74
75
76
77
78
79
80
81
82
83
84
85
86
87
88
89
90
91
|
from pymongo import MongoClient
from bs4 import BeautifulSoup
import requests
import time
host = 'localhost'
port = 27017
client = MongoClient(host,port)
db = client['db']
url_sheet = db['url_sheet']
info_sheet = db['info_sheet']
Base_Url = ['http://gz.58.com/shoujihao/pn{}/'.format(str(i)) for i in range(1,11)]
headers = {
'Cookie':'...'
}
titleSel = '#infolist > div > ul > div > ul > li > a > strong'
def checkNumber(num):
for i in range(0,len(num)):
if num[i] < '0' or num[i] > '9':
return (False)
else:
pass
return (True)
tempOut = open('out.txt','w')
def Get_Url(url):
time.sleep(0.5)
wb_data = requests.get(url, headers=headers)
soup = BeautifulSoup(wb_data.text,'lxml')
hrefs = soup.select(hrefSel)
for p in hrefs:
if p.get_text().strip().find('精准') == -1:
number = p.get_text().strip().replace('\n',' ').replace('\t',' ').replace(' ',' ').split(' ')[0]
if len(number) == 11:
url_sheet.insert_one(dict(number = number,url = p.get('href')))
else:
pass
else:
pass
TestInfoUrl = 'http://gz.58.com/shoujihao/26973010446666x.shtml?psid=192625604192771088616429809&entinfo=26973010446666_0'
PhoneSel = '#main > div.col.detailPrimary.mb15 > div.col_sub.mainTitle > h1'
ConnectSel = '#t_phone'
PutinTimeSel = '#main > div.col.detailPrimary.mb15 > div.col_sub.mainTitle > div > ul.mtit_con_left.fl > li.time'
def test404():
f = open('hehe.html','r')
soup = BeautifulSoup(f,'lxml')
str = soup.find_all('script')[-1].get_text()
if str[-6:-3] == '404':
print('404')
def Get_Info(url = TestInfoUrl):
time.sleep(1)
wb_data = requests.get(url, headers=headers)
soup = BeautifulSoup(wb_data.text,'lxml')
str = soup.find_all('script')[-1].get_text()
if str[-6:-3] == '404':
print('404')
pass
else:
Phone = soup.select(PhoneSel)[0].get_text().replace('\n',' ').strip()[:11]
cto = soup.select(ConnectSel)[0].get_text().replace('\n',' ').strip()
timer = soup.select(PutinTimeSel)[0].get_text().replace('\n',' ').strip()
info_sheet.insert_one(dict(number=Phone,ConnectNumber=cto,PostTime=timer,Url=url))
def main():
for pU in Base_Url:
Get_Url(pU)
for url in url_sheet.find():
Get_Info(url['url'])
if __name__ == '__main__':
main()
|
课程Code 笔记:分成两个爬虫分别爬取
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
|
def get_links_from(channel, pages, who_sells=0):
list_view = '{}{}/pn{}/'.format(channel, str(who_sells), str(pages))
...
if soup.find('td', 't'):
...
else:
pass
def get_item_info(url):
no_longer_exist = '404' in soup.find('script', type="text/javascript").get('src').split('/')
if no_longer_exist:
pass
else:
title = soup.title.text
price = soup.select('span.price.c_f50')[0].text
date = soup.select('.time')[0].text
area = list(soup.select('.c_25d a')[0].stripped_strings) if soup.find_all('span', 'c_25d') else None
item_info.insert_one({'title': title, 'price': price, 'date': date, 'area': area, 'url': url})
print({'title': title, 'price': price, 'date': date, 'area': area, 'url': url})
|
总结
这节课在前几节内容上拓展了页面防错.
另外url页面爬取难度也变大了..有了很多很多的判断
两个爬虫的同时应用充分展现了数据库的魅力
权当复习和练手吧hhh level up~~~
今天七夕诶,祝情成眷
