client = MongoClient(host,port) db = client['test'] sheet = db['sheet'] for i in range(1001): print(i) sheet.insert_one({ 'name': 'name' + str(i), 'age': i })
2016-08-08T14:29:35.978+0800 csv flag is deprecated; please use --type=csv instead 2016-08-08T14:29:35.986+0800 connected to: localhost 2016-08-08T14:29:36.010+0800 exported 528 records # 存在mongoexport相同文件夹下,效果如下
#数据导入 db.createCollection('log') show collections
mongoimport -d local(数据库名称) -c log(Collection名称) --file startup_log.json(导出文件名称) mongoimport -d local(数据库名称) -c log(Collection名称) --type csv --headerline --file startup_log.csv(导出文件名称) #validating settings: must specify --fields, --fieldFile or --headerline to import this file type
with open(path,'r') as f: lines = f.readlines() for index, line in enumerate(lines): data = dict(index=index,line=line,words=len(line.split())) #print(data) 检查是否读取.. sheet_tab.insert_one(data) # 存储数据
for item in sheet_tab.find(): print(item) #{'_id': ObjectId('57a80116d6616918def0fbfa'), 'index': 9703, 'words': 1, 'line': '.\n'} # 检查数据是否存入 # 另一种方法 refresh数据库插件
for item in sheet_tab.find({'words':0}): print(item['line'])
#-*- coding: utf8 -*- from bs4 import BeautifulSoup import requests import time
PriceSel = '#page_list > ul > li > div.result_btm_con.lodgeunitname > span.result_price > i' TitleSel = '#page_list > ul > li > div.result_btm_con.lodgeunitname > div > a > span' CommentSel = '#page_list > ul > li > div.result_btm_con.lodgeunitname > div > em > span' UrlSel = '#page_list > ul > li > div.result_btm_con.lodgeunitname' PlaceSel = '#page_list > ul > li > div.result_btm_con.lodgeunitname > div > em'
Testurl = 'http://cs.xiaozhu.com'# attention for adding http:// headers = { 'User-Agent' : 'Mozilla/5.0 (Macintosh; Intel Mac OS X 10_11_5) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/51.0.2704.103 Safari/537.36', 'Cookie' : 'abtest_ABTest4SearchDate=b; _gat_UA-33763849-7=1; __utmt=1; xzuuid=b2e6cf19; OZ_1U_2282=vid=v7a566a4734c93.0&ctime=1470629052<ime=1470629048; OZ_1Y_2282=erefer=https%3A//www.baidu.com/link%3Furl%3DqGXg8_L7_OKuYp3jvCSU2LCcrIH5r8_CN22-4NrCKWWUCQRu4q4wOdeB4q2b_Zg9%26wd%3D%26eqid%3Db72a32fa000083cd0000000557a80293&eurl=http%3A//www.xiaozhu.com/&etime=1470628619&ctime=1470629052<ime=1470629048&compid=2282; _ga=GA1.2.206747787.1470457508; __utma=29082403.206747787.1470457508.1470469908.1470628620.3; __utmb=29082403.4.10.1470628620; __utmc=29082403; __utmz=29082403.1470628620.3.2.utmcsr=baidu|utmccn=(organic)|utmcmd=organic' }
for price,title,comment,url,place in zip(prices,titles,comments,urls,places): data = dict(price=price.get_text(),title=title.get_text(), place=place.get_text().split('\n')[-1].strip(), comment=comment.get_text().split('\n')[1].strip(), url=url.get('detailurl'))
url = ['http://cs.xiaozhu.com/search-duanzufang-p{}-0/'.format(str(i)) for i in range(1,4)]
Testurl = 'http://cs.xiaozhu.com'# attention for adding http:// headers = { 'User-Agent' : 'Mozilla/5.0 (Macintosh; Intel Mac OS X 10_11_5) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/51.0.2704.103 Safari/537.36', 'Cookie' : 'abtest_ABTest4SearchDate=b; _gat_UA-33763849-7=1; __utmt=1; xzuuid=b2e6cf19; OZ_1U_2282=vid=v7a566a4734c93.0&ctime=1470629052<ime=1470629048; OZ_1Y_2282=erefer=https%3A//www.baidu.com/link%3Furl%3DqGXg8_L7_OKuYp3jvCSU2LCcrIH5r8_CN22-4NrCKWWUCQRu4q4wOdeB4q2b_Zg9%26wd%3D%26eqid%3Db72a32fa000083cd0000000557a80293&eurl=http%3A//www.xiaozhu.com/&etime=1470628619&ctime=1470629052<ime=1470629048&compid=2282; _ga=GA1.2.206747787.1470457508; __utma=29082403.206747787.1470457508.1470469908.1470628620.3; __utmb=29082403.4.10.1470628620; __utmc=29082403; __utmz=29082403.1470628620.3.2.utmcsr=baidu|utmccn=(organic)|utmcmd=organic' }
PriceSel = '#page_list > ul > li > div.result_btm_con.lodgeunitname > span.result_price > i' TitleSel = '#page_list > ul > li > div.result_btm_con.lodgeunitname > div > a > span' CommentSel = '#page_list > ul > li > div.result_btm_con.lodgeunitname > div > em > span' UrlSel = '#page_list > ul > li > div.result_btm_con.lodgeunitname' PlaceSel = '#page_list > ul > li > div.result_btm_con.lodgeunitname > div > em'
for price,title,comment,url,place in zip(prices,titles,comments,urls,places): data = dict(price=price.get_text(),title=title.get_text(), place=place.get_text().split('\n')[-1].strip(), comment=comment.get_text().split('\n')[1].strip(), url=url.get('detailurl')) sheet_out.insert_one(data)
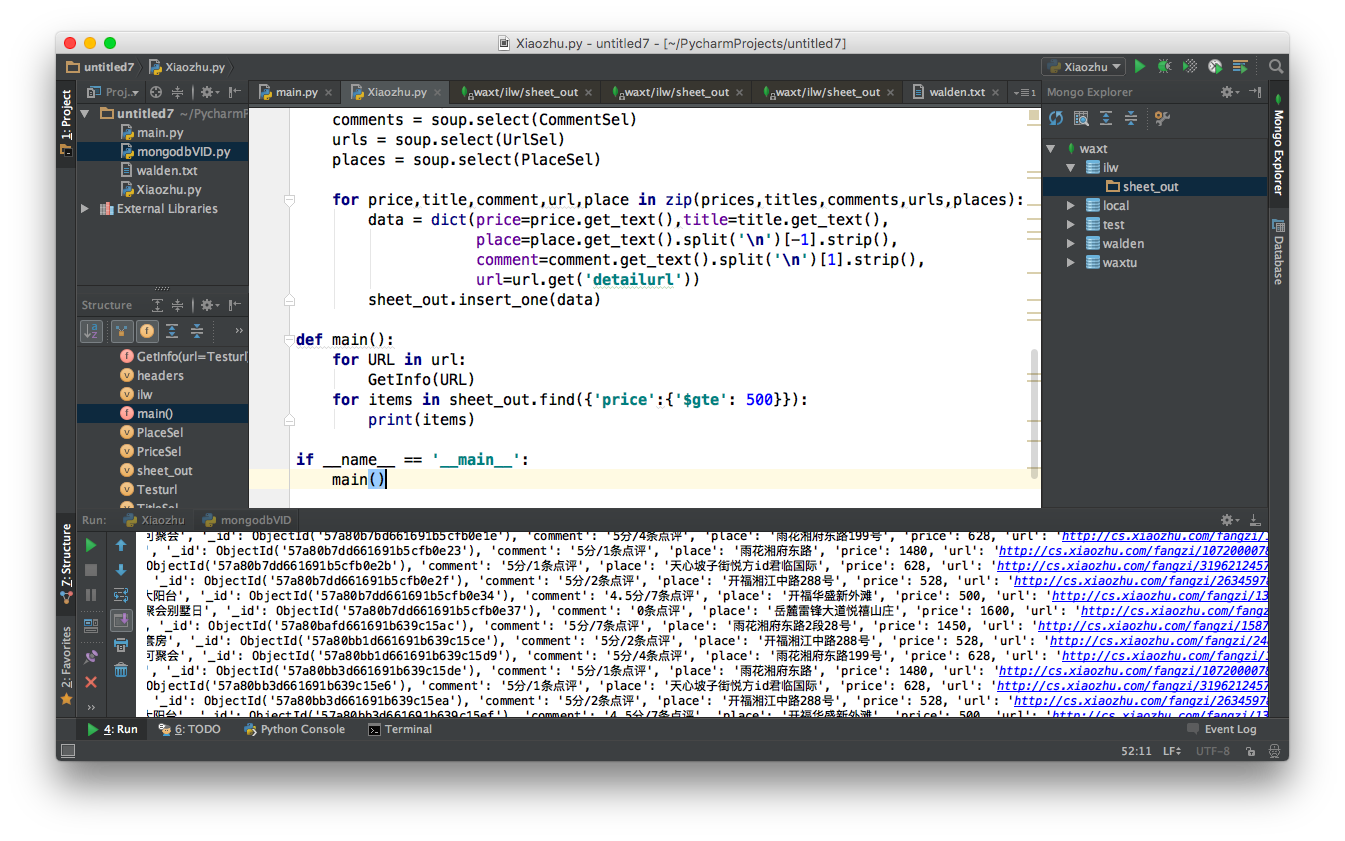
defmain(): for URL in url: GetInfo(URL) for items in sheet_out.find({'price':{'$gte': 500}}): print(items)